If open data is the new gold, why even those who release fail to reuse it? We created an open collaboration of data curators and open-source developers to dig into novel open data sources and/or increase the usability of existing ones. We transform reproducible research software into research- as-service.
Every year, the EU announces that billions and billions of data are now “open” again, but this is not gold. At least not in the form of nicely minted gold coins, but in gold dust and nuggets found in the muddy banks of chilly rivers. There is no rush for it, because panning out its value requires a lot of hours of hard work. Our goal is to automate this work to make open data usable at scale, even in trustworthy AI solutions.
Most open data is not public, it is not downloadable from the Internet – in the EU parlance, “open” only means a legal entitlement to get access to it. And even in the rare cases when data is open and public, often it is mired by data quality issues. We are working on the prototypes of a data-as-service and research-as-service built with open-source statistical software that taps into various and often neglected open data sources.
We are in the prototype phase in June and our intentions are to have a well-functioning service by the time of the conference, because we are working only with open-source software elements; our technological readiness level is already very high. The novelty of our process is that we are trying to further develop and integrate a few open-source technology items into technologically and financially sustainable data-as-service and even research-as-service solutions.
We are taking a new and modern approach to the data observatory concept, and modernizing it with the application of 21st century data and metadata standards, the new results of reproducible research and data science. Various UN and OECD bodies, and particularly the European Union support or maintain more than 60 data observatories, or permanent data collection and dissemination points, but even these do not use these organizations and their members open data. We are building open-source data observatories, which run open-source statistical software that automatically processes and documents reusable public sector data (from public transport, meteorology, tax offices, taxpayer funded satellite systems, etc.) and reusable scientific data (from EU taxpayer funded research) into new, high quality statistical indicators.

- We are building various open-source data collection tools in R and Python to bring up data from big data APIs and legally open, but not public, and not well served data sources. For example, we are working on capturing representative data from the Spotify API or creating harmonized datasets from the Eurobarometer and Afrobarometer survey programs.
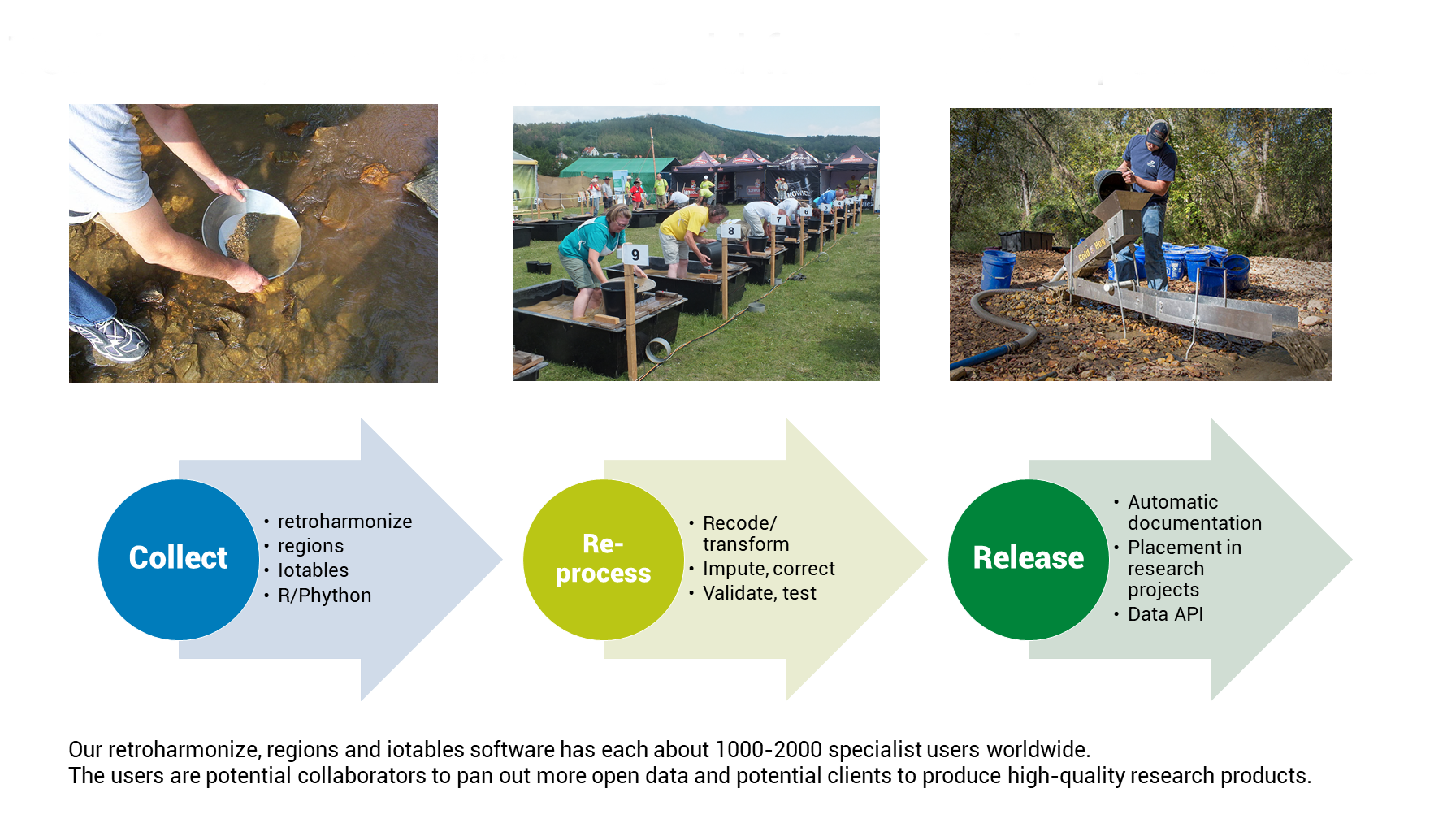
- Open data is usually not public; whatever is legally accessible is usually not ready to use for commercial or scientific purposes. In Europe, almost all taxpayer funded data is legally open for reuse, but it is usually stored in heterogeneous formats, processed into an original government or scientific need, and with various and low documentation standards. Our expert data curators are looking for new data sources that should be (re-) processed and re-documented to be usable for a wider community. We would like to introduce our service flow, which touches upon many important aspects of data scientist, data engineer and data curatorial work.
- We believe that even such generally trusted data sources as Eurostat often need to be reprocessed, because various legal and political constraints do not allow the common European statistical services to provide optimal quality data – for example, on the regional and city levels.
- With rOpenGov and other partners, we are creating open-source statistical software in R to re-process these heterogenous and low-quality data into tidy statistical indicators to automatically validate and document it.
- We are carefully documenting and releasing administrative, processing, and descriptive metadata, following international metadata standards, to make our data easy to find and easy to use for data analysts.
- We are automatically creating depositions and authoritative copies marked with an individual digital object identifier (DOI) to maintain data integrity.
- We are building simple databases and supporting APIs that release the data without restrictions, in a tidy format that is easy to join with other data, or easy to join into databases, together with standardized metadata.
- We maintain observatory websites (see: Digital Music Observatory, Green Deal Data Observatory, Economy Data Observatory) where not only the data is available, but we provide tutorials and use cases to make it easier to use them. Our mission is to show a modern, 21st century reimagination of the data observatory concept developed and supported by the UN, EU and OECD, and we want to show that modern reproducible research and open data could make the existing 60 data observatories and the planned new ones grow faster into data ecosystems.
We are working around the open collaboration concept, which is well-known in open source software development and reproducible science, but we try to make this agile project management methodology more inclusive, and include data curators, and various institutional partners into this approach. Based around our early-stage startup, Reprex, and the open-source developer community rOpenGov, we are working together with other developers, data scientists, and domain specific data experts in climate change and mitigation, antitrust and innovation policies, and various aspects of the music and film industry.
,[developers](/authors/developer/) and [service designers](/authors/team/), even volunteers and citizen scientists are welcome to join.](/media/img/observatory_screenshots/dmo_contributors.png)
Our open collaboration is truly open: new data curators, data scientists and data engineers are welcome to join. We develop open-source software in an agile way, so you can join in with an intermediate programming skill to build unit tests or add new functionality, and if you are a beginner, you can start with documentation and testing our tutorials. For business, policy, and scientific data analysts, we provide unexploited, exciting new datasets. Advanced developers can join our development team: the statistical data creation is mainly made in the R language, and the service infrastructure in Python and Go components.
Daniel Antal
Data Scientist & Founder of the Digital Music Observatory
My research interests include reproducible social science, economics and finance.